
W 2011 roku analitycy firmy McKinsey oszacowali, że ilość danych produkowanych w ciągu roku przez globalny biznes i społeczeństwo odpowiada informacyjnej objętości 60 tysięcy Bibliotek Kongresu USA. Jednocześnie badacze podkreślają, że produkcja danych rośnie w tempie wykładniczym, a według ostatniej oceny IBM ilość danych, jaka została wytworzona przez cały rok 2010, jest obecnie generowana w kilka dni.
Ogromna skala utrudniająca ich badanie jest definicyjną cechą zjawiska „wielkich danych” („big data”). Obecnie mamy do czynienia z sytuacją, w której coraz więcej różnego rodzaju obiektów – ludzi, urządzeń, instytucji, firm – funkcjonuje pozostawiając elektroniczne ślady. Są one gromadzone w przepastnych bazach danych i stanowią specyficzny produkt uboczny cywilizacji.
Pozostałe cechy „big data” to:
- złożony charakter produkowanych i przechowywanych danych. Są one w większośći słabo ustrukturyzowane, najczęściej nie są opatrzone metadanymi ułatwiającymi analizy (np. tagami lub słowami kluczowymi), a poszczególne zbiory nie są ze sobą powiązane, co utrudnia ich ogląd i badanie;
- szybkość z jaką dane są generowane i zmieniane;
- potrzeba krytycznego podejścia do rzetelności danych.
„Wielkie dane”, przy całej swej skali i złożoności, nie są bynajmniej nieużytecznymi „odpadkami cywilizacji”. Przeciwnie, w postindustrialnej ekonomii uważane są za odpowiednik ropy naftowej; są zasobem którego umiejętne wydobycie i przetworzenie może okazać się niezwykle cenne dla biznesu, instytucji publicznych i poszczególnych osób. Złożoność danych ma być odpowiedzią na złożone problemy współczesnego świata.
Proces
Wydobycie wartości z surowych danych jest skomplikowanym procesem. Każdy z jego etapów wymaga specyficznej wiedzy i umiejętności. Nie zawsze dane są bezpośrednio dostępne dla analityka, często trzeba je pozyskać z zewnętrznych źródeł – głównie z Internetu (na przykład z portali społecznościowych) lub z publicznie dostępnych baz danych. Kolejnym, bardzo istotnym etapem, jest wstępne przetwarzanie informacji. Często dane nie są przechowywane w postaci dogodnej do prowadzenia dalszych analiz; bywają zawarte w różnych plikach i bazach danych, które stosują wzajemnie niekompatybilne formaty Przed przystąpieniem do jakichkolwiek analiz należy zatem scalić surowe dane i przekształcić je do postaci, która będzie pozwalała przeprowadzić konkretne analizy. Właśnie na tym etapie pojawiają się zwykle problemy związane z ilością i dynamiką danych. Aby im sprostać, w tworzeniu architektury zasilania danymi systemów analitycznych często stosuje się zaawansowane technologie oparte na przykład na rozpraszaniu i/lub paralelizacji procesów przetwarzania danych.
Dopiero po wstępnej obróbce danych – która jest inżynieryjnym wyzwaniem sama w sobie – można przystąpić do podjęcia właściwych analiz. Generują one wiedzę i wartość przez redukcję złożoności zebranych danych oraz dzięki odnajdywaniu znaczących relacji w nich zawartych. Już sama możliwość wygenerowania „na żądanie” mniej lub bardziej zaawansowanych statystyk opisujących duże ilości informacji (na przykład o firmie, jak ma to miejsce w rozwiązaniach Business Intelligence), stanowi nieocenioną wartość dla przedsiębiorstw, umożliwiając podejmowanie adekwatnych i szybkich biznesowych decyzji.
Nauka o danych dysponuje także o wiele bardziej zaawansowanymi narzędziami. Pozwalają one odnajdywać różnego rodzaju wzory w analizowanych danych lub klasyfikować je według wcześniej zdefiniowanych kategorii. Dzięki temu złożona rzeczywistość, odzwierciedlona w zbiorach danych, zostaje zredukowana do mniejszej ilości wymiarów, które są
znaczące dla ludzkiego aparatu poznawczego i na podstawie których można już podejmować decyzje. Co więcej, zidentyfikowanie stabilnych wzorów relacji między różnymi wymiarami danych pozwala na formułowanie przewidywań na temat przyszłych stanów rzeczy. Wciąż rozwijane są nowe metody analiz specyficznych domen i rodzajów danych – od przetwarzania języka naturalnego, przez analizy relacji społecznych po wnioskowanie na podstawie sieci relacji semantycznych między obiektami.
Ostatnim etapem procesu analiz „dużych danych” jest komunikacja i wykorzystanie ich wyników, na przykład w postaci interaktywnej wizualizacji na stronie internetowej, rozbudowanego raportu, koncepcji nowego produktu czy kampanii marketingowej. Wiedza powstająca dzięki nauce o danych może być spożytkowana na wiele sposobów, w różnych dziedzinach życia.
Umiejętności
Prowadzenie tak złożonego procesu analitycznego wymaga unikalnego zestawu umiejętności i doświadczeń. Najlepiej pokazuje to popularny w kręgach nauki o danych „diagram Venna dla Data Science”:
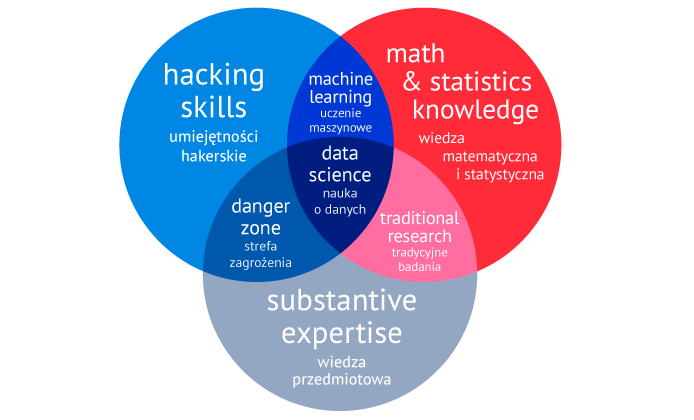
Współczesne projekty analiz dużych ilości danych wykorzystują trzy różne zestawy kompetencji. „Umiejętności hakerskie”, czyli znajomość systemów operacyjnych, baz danych, języków programowania w stopniu umożliwiającym elastyczne i kreatywne rozwiązywanie problemów, są wymagane na każdym etapie projektu – nie tylko podczas wstępnego pozyskiwania danych i ich transformacji, ale także na etapie właściwej analizy, ta ostatnia bowiem jest zwykle wykonywana programistycznie, z użyciem wyspecjalizowanych języków bądź modułów statystycznych. Dotyczy to także tworzenia wizualizacji używanych do komunikowania rezultatów analiz
Nauka o danych to wiedza matematyczna i statystyczna. Analizowanie dużych, wielowymiarowych zbiorów danych wymaga doświadczenia w posługiwaniu się wysoce zaawansowanymi metodami i technikami, których asortyment wciąż się rozszerza, wraz z pojawianiem się nowych rodzajów przetwarzanych informacji i potencjalnych sposobów ich wykorzystania.
Trzecim niezbędnym elementem profilu badacza danych jest wiedza domenowa (dotycząca konkretnej dziedziny biznesu, nauki, problemów społecznych itp., której dotyczą analizowane dane), bo tylko dzięki niej można właściwie ukierunkować analizy i zinterpretować ich wyniki.
Rosnąca nieustannie ilość danych będących potencjalnym źródłem wartości w różnych dziedzinach życia z jednej strony, oraz złożoność profilu analityka danych z drugiej, decydują o dużym i wciąż rosnącym rynkowym zapotrzebowaniu na specjalistów od analizy „big data”. Dopiero od niedawna pojawiają programy edukacyjne nastawione na ich kompleksowe kształcenie, ale wciąż jeszcze analitycy danych to osoby specjalizujące się w dziedzinach szczegółowych (statystycy, informatycy lub osoby potrzebujące nowych narzędzi analiz problemów dziedzinach, którymi się zajmują), które często na własną rękę uzupełniają wiedzę i doświadczenie w pozostałych obszarach składających się na „data science”. Aby sprostać wyzwaniu, jakie stwarza nowa rzeczywistość danych – wykorzystać jej szanse i lepiej rozumieć ryzyka – należy tworzyć inicjatywy wspomagające tego typu kompleksowe kształcenie i podnoszenie umiejętności.
